This post is part of an ongoing series where I explore training large language models (LLMs)



Pre-training LLMs from Scratch: Scaling from 126M to 286M Parameters
A personal research project by Gilberto Batres-Estrada, Data Scientist at Helicon
This post is part of an ongoing series where I explore training large language models (LLMs) from scratch in my own research. While this work is independent and not affiliated with Helicon's operations, it sits at the intersection of topics I'm deeply passionate about: AI, compute efficiency, and the future of intelligent systems.
Moving to Cloud Infrastructure
As model size grows, so does the compute budget required. For this experiment I moved from a local setup to a cloud GPU instance running an NVIDIA H100. The full session, including environment setup, connecting to the code repository, running training, and saving a checkpoint to a private HuggingFace account , came in at just under one hour of active instance time, at a total cost of $4.30 USD.
The cost for training an LLM of 286 million parameters is what a regular cup of coffee costs in Sweden: cloud GPU time is billed from the moment the instance is active, not just during training. Workflow efficiency matters.
Scaling Laws: Why Bigger Models Need More Tokens
A well-established result in deep learning research is that model performance improves predictably as both model size and the number of training tokens increase. Two landmark papers underpin this:
- OpenAI documented this empirically in Scaling Laws for Neural Language Models
- Google DeepMind extended this work to derive rules for compute-optimal training : given a fixed compute budget, how should you allocate it between model size and token count? In Training Compute-Optimal Large Language Models we get some a recipe for answering this question.
The Experiment: 126M → 286M Parameters
The model follows a GPT architecture, consistent with earlier work in this series. The table below summarizes the key architectural parameters and model size.

Pre-training runs from randomly initialized weights for 10,000 steps, over approximately 655 million tokens.
We noted that increasing the number of parameters from 126M to 286M, increased the knowledge of the model. It can complete sentences, see the examples below, but still lacks intelligence. From today’s frontier models, it is not a hard conclusion to make, this is how frontier labs develop their models, by increasing training tokens and model parameters.
Results
Training and validation loss both decrease as expected, confirming the model is learning to predict the next token correctly.
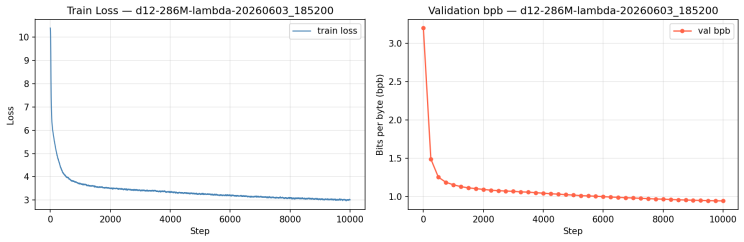
The bits-per-byte (BPB) metric measures how efficiently the model compresses and predicts text , lower is better:
| Split | BPB |
| Training | 0.8921 |
| Validation | 0.9425 |
Conditioned Text Generation
To qualitatively assess the model, I ran a simple conditioned completion test: provide the beginning of a sentence and let the model continue it. A capable model produces plausible continuations; an undertrained one produces incoherence.
Prompts used:
"The capital of France is"
"The chemical symbol of gold is"
"If yesterday was Friday, then tomorrow will be"
"The opposite of hot is"
"The planets of the solar system are:"
"My favorite color is"
"If 5*x + 3 = 13, then x is"At 286M parameters and 10k training steps, the model has picked up grammatical structure but not yet logical reasoning. A common failure mode at this scale and token count is repetition loops, the model gets stuck regenerating the same tokens, a well-known symptom of insufficient training.

Takeaways
This experiment raises practical questions worth exploring:
- Is there value in training your own models rather than relying on frontier or open-source alternatives?
- What are the real compute costs at different scales?
- When do custom-trained models become competitive?
The scaling laws literature gives us a framework: models improve with more compute, more tokens, and larger architectures , but the curve is predictable, which means we can reason about costs and capabilities before committing resources.
Next steps will push token count and training duration further, to see at what point these toy models start producing coherent reasoning.
This is independent research and does not represent the views or work of Helicon.