
Introduction
In previous posts, we’ve explored how Large Language Models (LLMs) can power AI agents to solve real-world problems — particularly in the energy industry. Generative AI is transforming how we work, and AI agents become even more valuable when paired with specialized tools.
Frameworks like LangChain and Anthropic’s Model Context Protocol (MCP) help us build these tool-augmented agents. One effective approach is using the LLM as an intent classifier: rather than solving tasks directly, the LLM identifies the user’s intent and delegates execution to a specialized tool.
This strategy works particularly well in well-defined domains, where tasks can be broken down into sequential steps and managed with clear guardrails. In fact, we’ve found that sequential workflows often outperform fully autonomous agents.
In this post, we introduce a powerful forecasting tool that fits into this architecture: Chronos, a pre-trained large language model for time series forecasting.
The Forecasting Tool
Imagine asking your agent:

There are several ways to handle this:
- Pass your data (e.g., as a CSV file) to a chatbot from a major provider
- Build a custom app that uses AI APIs and tools like MCP alongside your proprietary forecasting models
- Or: Use a pre-trained model like Chronos that specializes in time series prediction
In our setup, the agent performs intent classification. If the query involves prediction, the agent hands off control to a system component that runs Chronos. This modular setup keeps the LLM lightweight, with external modules handling specific tasks.
In this blog post, we focus on evaluating Chronos’ performance in a zero-shot setting — meaning without any retraining on our specific datasets.
Model: Amazon Chronos
There are several open-weight LLMs trained for time series forecasting. We chose Chronos, presented by Amazon in their paper Chronos: Learning the Language of Time Series.
Chronos is based on the T5 encoder-decoder architecture and was trained on a wide range of time series datasets. One key feature is its zero-shot prediction ability — meaning it can make forecasts on unseen datasets without retraining. This is especially valuable when you have limited historical data.
Factors to Consider When Choosing a Model
When selecting a forecasting model, important factors include:
- Hardware requirements: Can you run it on your available CPU or GPU?
- Budget: Both in terms of time and cost
- Data availability: How much historical data you have
Data availability often dictates what kind of model you can use. If you only have a small dataset, deep learning models might not be appropriate because they typically require large amounts of data. Conversely, pre-trained models like Chronos offer the advantage of generating meaningful predictions even with very little data.
However, be aware: certain types of time series, such as stock market data or weather data, are inherently more challenging due to their high stochasticity. Such datasets require careful validation to avoid pitfalls like lookahead bias.
Experiments and Setup
Data
We recommend reserving a small portion of your data for independent testing. This practice helps you identify scenarios where the model may fail — a critical step for robust deployment.
For our experiments, we used the same datasets as in previous posts, particularly the PJM Interconnection LLC dataset. PJM serves parts of Delaware, Illinois, Indiana, Kentucky, Maryland, Michigan, New Jersey, North Carolina, Ohio, Pennsylvania,
Tennessee, Virginia, West Virginia, and the District of Columbia.
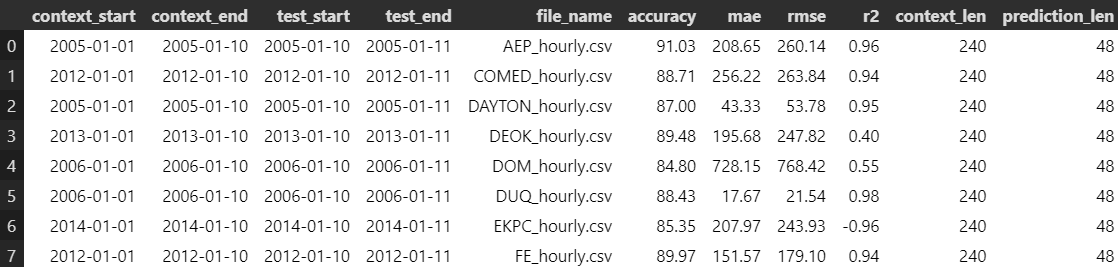
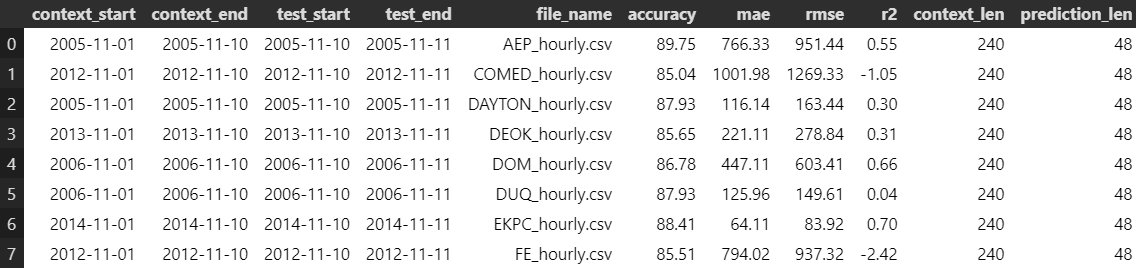
In each case, we asked Chronos to forecast 48 hours ahead, and we compared its predictions against the actual data.
Below are some visualizations from our experiments:
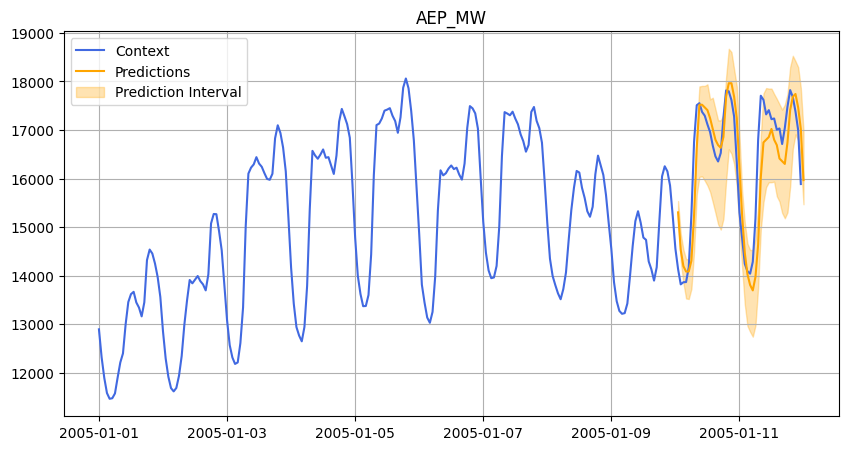
2005.
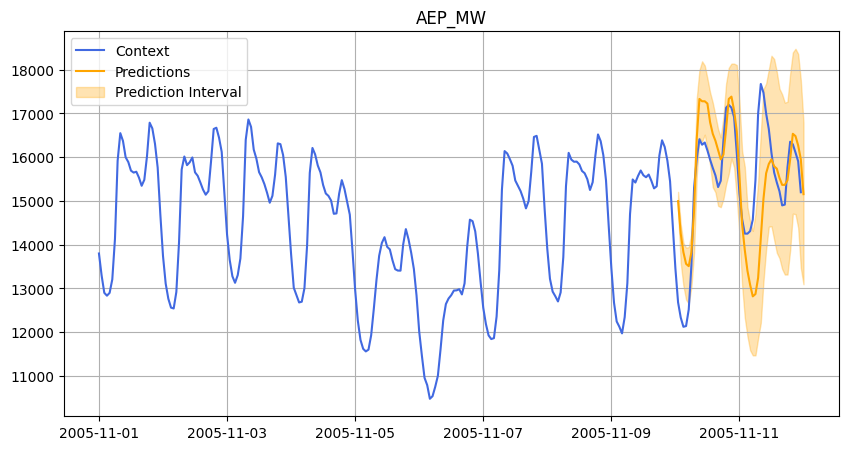
November 2005.
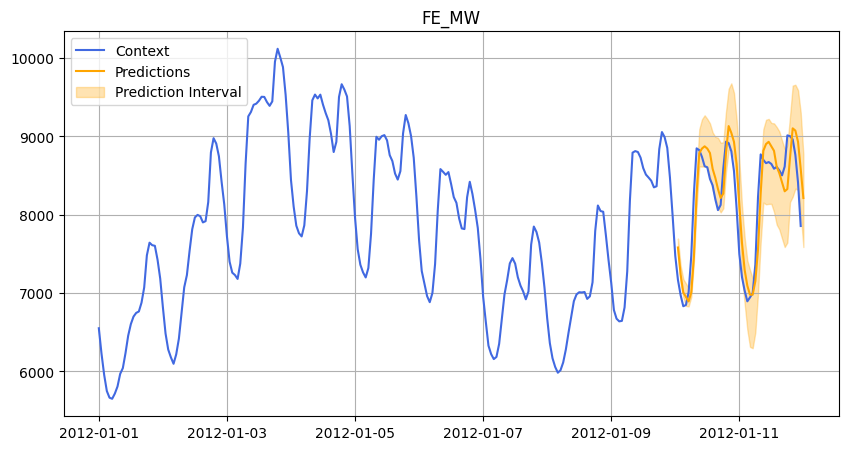
2012.
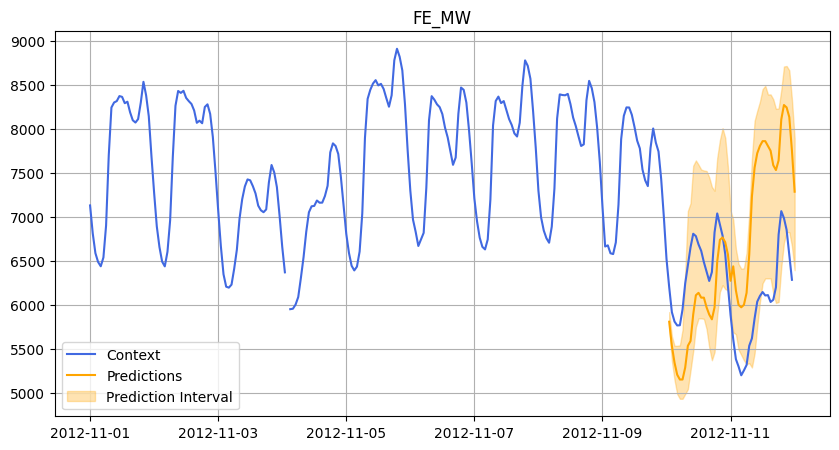
2012.
Metrics
To evaluate performance, we used:
- Accuracy
- Mean Absolute Error (MAE)
- Root Mean Squared Error (RMSE)
- R² Score
Ideally, Accuracy and R² should be close to 100% and 1.0, respectively, while MAE and RMSE should approach 0. Chronos showed mixed results. For example:
- On the FE dataset, the model performed well in January (Accuracy 86.26%, good R²) but poorly in November (R² of -2.42).
- This highlights why it’s crucial to use multiple metrics when evaluating models, not just a single number.
January Results
November Results
Appendix: Challenging Datasets
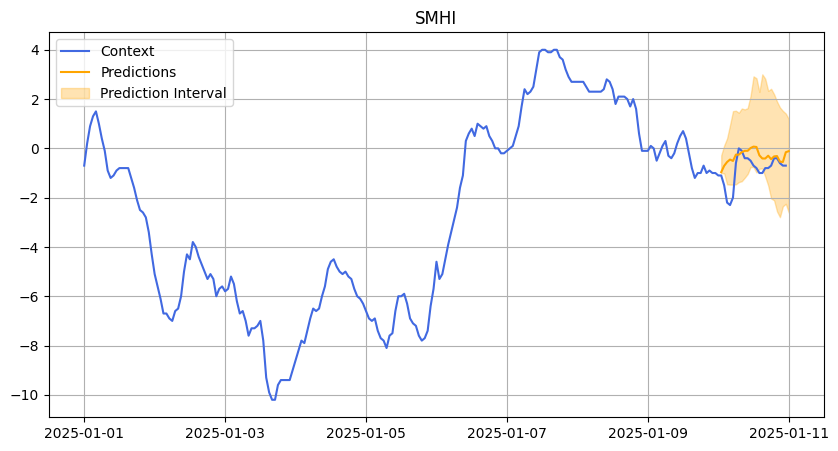
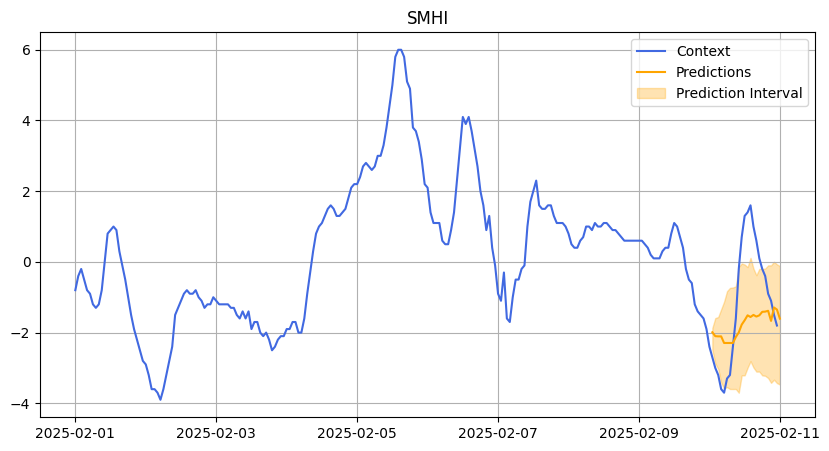
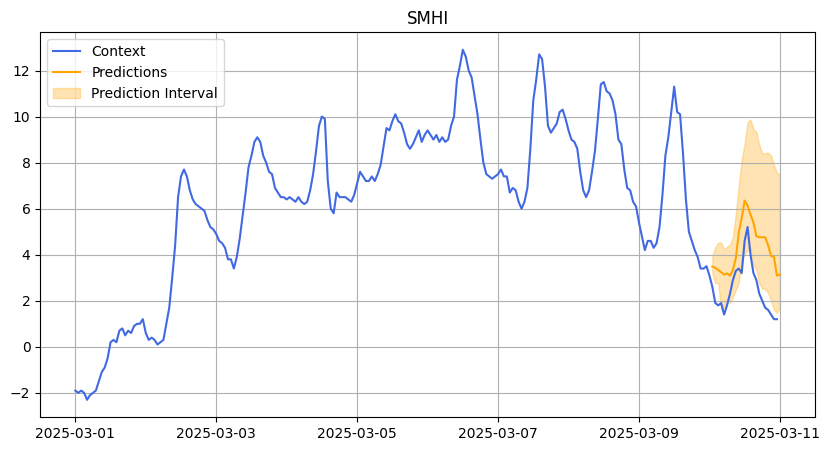
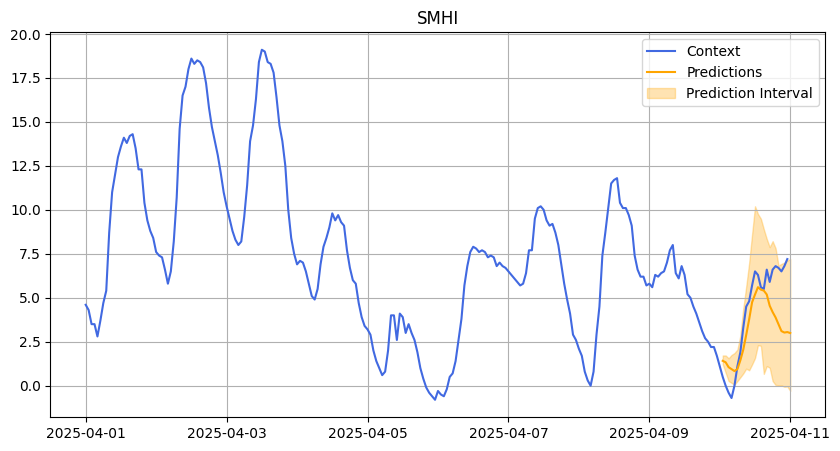
We also evaluated Chronos on a more difficult dataset: temperature data from Stockholm provided by the Swedish Meteorological and Hydrological Institute (SMHI).
Weather forecasting is extremely challenging because of the chaotic nature of weather systems — much like predicting stock returns.
In this case, accuracy was not a suitable metric because the temperature values could be negative. Instead, we focused on the R² score to assess prediction quality. The R² shows that Chronos struggled with predictions leading to not so good results. As weather data is so challenging, we decided to change the prediction length from 48 to 24 hours.

SMHI January
SMHI February
SMHI March
SMHI April
Key Takeaways
- Pre-trained models like Chronos can deliver fast and efficient forecasting, even with small datasets.
- Independent evaluation is critical to spot weak areas and improve robustness.
- Metric selection matters: never rely on a single metric.
- Forecasting chaotic data (like weather and stock prices) remains an open challenge, even for state-of-the-art models.
When integrating pre-trained models into AI pipelines, ongoing evaluation is just as important as when developing models from scratch.