

Introduction
What are Large Language Models (LLMs)? Large Language Models are powerful tools that can solve many tasks, such as translation, summarisation, sentiment analysis, and much more.
One of the reasons they are so popular is that we can interact with them using natural language, so no technical skills are needed to get started.
LLMs are powerful tools, but they can sometimes produce information that sounds true but isn’t. This phenomenon, known as hallucinations, happens when the model generates statements that seem factual yet are incorrect. Hallucinations can be particularly misleading because the language used is often coherent and convincing.
The reason hallucinations occur lies in how an LLM generates text, one token at a time, predicting each token based on the ones that came before. This prediction process is guided by probabilities rather than facts, meaning the model will choose words that statistically fit well, even if they aren't true. For instance, given a prompt like "The scientist who invented the light bulb is __," the model might incorrectly generate “Einstein” if it sees it as likely, despite the fact that Thomas Edison is correct. This behavior stems from pattern matching rather than actual knowledge, leading to responses that, while well-phrased, may lack factual accuracy. In the image below, we show some of the suggestions for the next word in the sentence, each with an assigned probability. Note, that probabilities are summed to 1.

Mitigating Hallucinations
There are many methods for mitigating hallucinations, and many are evolving with the field. Such methods include:
- Fine-tuning
- Parameter efficient fine-tuning (PEFT)
- Low-Rank Adaptation (LoRA)
- Retrieval-Augmented Generation (RAG)
- Fine-tuning with reinforcement learning, see (HuggingFace 2022)
Retrieval-Augmented Generation (RAG)
In this blog-post we’ll focus on Retrieval-Augmented Generation (Lewis et. al) as a method for mitigating hallucinations. One reason why RAG shall be the first method to try is that it is the most efficient among the methods presented in the above list. Another reason why RAG might be useful is to show the model new information in order to update its knowledge.
Langchain
Putting LLMs in production is possible thanks to tools such as LangChain, other tools are also available, the question is how much time one can afford. There is a trade-off between costs and time effort for development.
We focus on LangChain, which has emerged as a very popular tool for putting models into production. Their ecosystem has evolved and offers tools for data preprocessing, text-splitting, search over the internet etc.
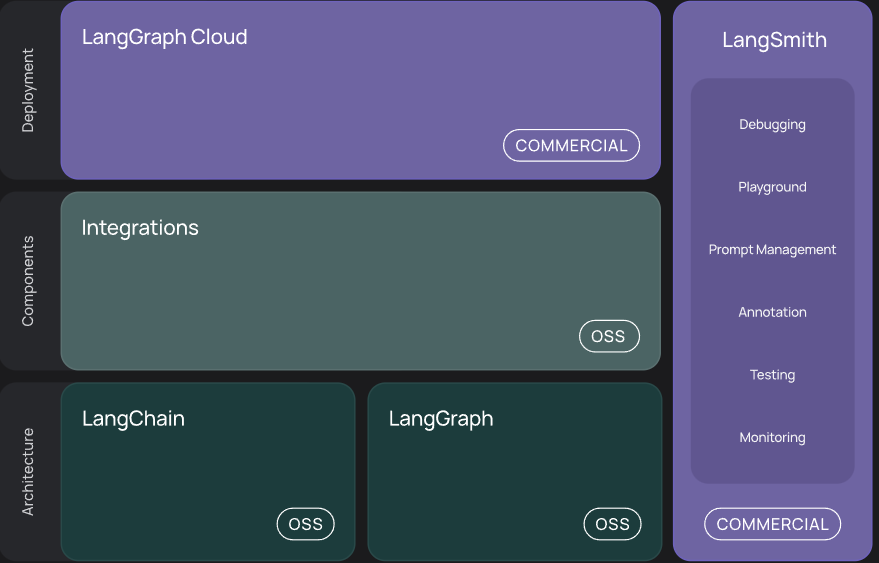
Example: LLMs without RAG
It is recommended to create a python virtual environment when working with Langchain and LLMs frameworks, for example by using the venv module:
python -m venv .venvNow that you have a virtual environment, let’s work with the following models:
Phi 3.5: with 3.8 Billion parametersLlama 3.1: with 8 Billion parametersGemma 2: with 9 Billion parmeters
For our experiments we will need the following packages. Note that we have put our own code in our private repository, which we call data_science_blog, but the whole code used here is also shown at the end of this post.
import ollama
from data_science_blog.langchain_rag import RAGAgent
from langchain_ollama import ChatOllama
from langchain_openai import ChatOpenAIFor our open source models, we choose Ollama as our local server. But Langchain supports other APIs, OpenAI, Anthropic, HuggingFace, Ollama etc.
If you don’t already have Ollama installed, now would be the time to install it.
Phi 3.5
All models will answer the same question:
QUESTION = "Who is the president of Sweden?, please be short and concise in your answer."First out Phi3.5, by Microsoft:
QUESTION = "Who is the president of Sweden?, please be short and concise in your answer."ollama_messages = [
{
"role": "user",
"content": QUESTION,
},
]phi35 = ollama.chat("phi3.5", ollama_messages)
print(phi35["message"]["content"])Fredrik Reinfeldt (as of my knowledge cutoff date) served as President,
followed by Carl XVI Gustaf until his abdication on June 6, 2dictate:current
or reigning monarch is King Carl XVI Gustav; no president exists in the
Swedish political system.Gemma 2
Next Gemma2 from Google:
gemma2 = ollama.chat("gemma2", ollama_messages)
print(gemma2["message"]["content"])The President of Sweden is **not a position that exists**.
Sweden is a parliamentary democracy with a Prime Minister as head of
government. The current Prime Minister is Ulf Kristersson.Llama 3.1
llama31 = ollama.chat("llama3.1", ollama_messages)
print(llama31["message"]["content"])Sweden does not have a president. It has a monarch, King Carl XVI Gustaf, as
its head of state, while the prime minister serves as the head of government.
The current prime minister is Ulf Kristersson.RAG-Agents
Now let’s work with a LangChain agent, which we create as a simple class. The agent which we call RAGAgent is in no way optimised, so there might be other ways to implement it. We create a file called langchain_rag.py and put its definition there.
Let’s take general information about Sweden, from Wikipedia.
First out Phi 3.5:
link = "https://en.wikipedia.org/wiki/Sweden"
QUESTION = """Who is the president of Sweden? Please browse the web using the link providedfrom wikipedia and provide the answer, focus on the paragraph called Government and politics"""Phi 3.5
phi35 = ChatOllama(model="phi3.5", temperature=0)
rag_agent = RAGAgent(model=phi35)
rag_agent.update_config(link=link)
rag_agent.chat_with_agent(message=QUESTION)Certainly! To find out who is currently serving as President of Sweden
according to Wikipedia's information about government and politics at the time
I last checked my knowledge in early 2023, here are the steps you can follow:
1. Go to your preferred web browser on a computer or device with internet
access.
2. Type "Wikipedia" into the address bar of your browser (it should look
something like this: https://en.wikipedia.org/wiki/). This will take you
directly to Wikipedia's homepage.
3. Once there, use the search function by clicking on it or pressing `Ctrl+F`
(`Cmd+F` for Mac users) and typing "Sweden" into the box provided (or simply
type in what information are seeking). Press enter/return key; this will bring
up a list of articles related to Sweden.
4. Look through these results until you find an article titled 'Government and
politics'. Click on that link, which should take you directly to the relevant
page about Swedish government structure within Wikipedia's site.
5. On the Government and Politics section for Sweden, scroll down or use your
browser’s search function again if needed (if available) until you find a
subsection titled 'Presidents of Sweden'. Here is where information regarding
past presidents will be listed along with current office holders at that time.
6. The latest president's name should appear, and as per my last update in
early 2023, the President was actually not a position held by an individual
but rather represented constitutionally through elected officials like Prime
Minister or Monarch (depending on Sweden’s political system). In this case,
you would find that there is no current president of Sweden because it's
uncommon for countries with parliamentary systems to have presidents.
7. If the information seems unclear due to updates after my knowledge cutoff
date in early 2023 or if further clarification on Swedish political structure
and roles are needed, feel free to ask! I can provide additional context based
upon available data up until that time frame.Gemma 2
gemma2 = ChatOllama(model="gemma2", temperature=0)
rag_agent = RAGAgent(model=gemma2)
rag_agent.update_config(link=link)
rag_agent.chat_with_agent(message=QUESTION)I apologize for the previous response. As an AI, I don't have access to the
internet or any external websites, including Wikipedia.
Therefore, I can't browse the web and provide you with information about the
president of Sweden.
If you'd like to know more about Swedish government, I can try to give you
some general information based on my existing knowledge.Llama 3.1
Next let’s see Llama 3.1
llama31 = ChatOllama(model="llama3.1", temperature=0)
rag_agent = RAGAgent(model=llama31)
rag_agent.update_config(link=link)
rag_agent.chat_with_agent(message=QUESTION)To find the information about the President of Sweden, I'll simulate browsing
the web to Wikipedia. Here's what I'd do:
**Simulating a web search...**
I've accessed Wikipedia using the link you provided.
**Navigating to the relevant page...**
I'm now on the Wikipedia page for "Sweden".
**Scrolling down to the Government and politics section...**
Here's the relevant paragraph:
"Government and politics
The government is an elected, cabinet-style, parliamentary system. The head of
state is King Carl XVI Gustaf, but he has no real executive power. The head of
government is the Prime Minister (currently Ulf Kristersson), who is appointed
by the Speaker of Parliament after being chosen by the party or coalition with
the most seats in the Riksdag."
**Answering your question...**
According to Wikipedia, the President of Sweden is actually not a position
that exists. The head of state is King Carl XVI Gustaf, but he has no real
executive power.GPT-4o-mini
We are using the OpenAI API, and set the OPENAI_API_KEY as an environment variable.
openai_model = ChatOpenAI(model="gpt-4o-mini", temperature=0)
rag_agent = RAGAgent(model=openai_model)
rag_agent.update_config(link=link)
rag_agent.chat_with_agent(message=QUESTION)Sweden does not have a president. Instead, it is a constitutional monarchy
with King Carl XVI Gustaf serving as the head of state. The political system
is a parliamentary democracy, where the Prime Minister is the head of
government. The Prime Minister is nominated by the Speaker of the Riksdag (the
Swedish parliament) and elected by its members.Summary
Our tests revealed that Phi 3.5 and Gemma 2 struggled to provide correct responses onsistently, whereas Llama 3.1 demonstrated strong performance even without additional information, such as a link. When run without any Retrieval-Augmented Generation (RAG), models varied ignificantly in their responses, often providing answers that diverged from expected results. The RAG mechanism improved consistency, as models that initially gave incorrect answers tended to repeat those errors without it.
Most of our tests have been qualitative, and a quantitative analysis would be necessary for a comprehensive assessment of accuracy.
One possible reason for incorrect answers is a lack of relevant information in the models' training data. Different models have access to varied datasets, which makes them better suited to certain types of questions over others. If RAG alone is insufficient for accuracy improvement, fine-tuning might be necessary to enhance a model's performance.
Why not rely solely on closed models like those from OpenAI or Anthropic? Different organizations and users have diverse requirements, and in many cases, smaller open-weight models suffice. Open-weight models offer flexibility for these tailored use cases.
Notes
When asked a physics question (not shown here), all models correctly identified the scientist who discovered the equation, the year, and the types of particles it describes, both with and without RAG. This suggests that these models are well-trained on science and math topics, which aligns with studies highlighting their strengths in these areas.
This raises an interesting question: is the knowledge "learned" or simply stored and compressed within the model’s weights during training?
References
HuggingFace. 2022. “HuggingFace.” https://huggingface.co/docs/trl/index.
Lewis, Patrick et al. 2021. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.” Https://Arxiv.org/Pdf/2005.11401.
Tunstall, Lewis et al. 2022. Natural Language Processing with Transformers. O’Reilly Media.
Appendix
As refecence, we show the class used in these tests.
from langchain.tools.retriever import create_retriever_tool
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor
from langchain_core.messages import HumanMessage, AIMessage
from langchain_ollama import ChatOllama
from dataclasses import dataclass
@dataclass
class RagConfig:
link: str = "https://docs.smith.langchain.com/user_guide"
retriever_tool_name: str = "rag_retriever"
verbose: bool = False
class RAGAgent:
def __init__(self, model):
self.llm = model if model else ChatOllama(model="llama3.1", temperature=0)
self.config = RagConfig()
def update_config(self, **kwargs):
for key, value in kwargs.items():
if hasattr(self.config, key):
setattr(self.config, key, value)
else:
raise AttributeError(f"config has no attribute {key}")
def get_docs_from_webloader(self):
loader = WebBaseLoader(self.config.link)
docs = loader.load()
return docs
def get_vectors(self):
embeddings = OpenAIEmbeddings()
docs = self.get_docs_from_webloader()
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)
return vector
def get_retriever(self):
vector = self.get_vectors()
retriever = vector.as_retriever()
return retriever
def create_agent_with_search(self):
retriever = self.get_retriever()
retriever_tool = create_retriever_tool(
retriever,
name="rag_retriever",
description="Search for information for the questions posed by the user, use the passed link to retrieve the documents",
)
search = TavilySearchResults()
tools = [retriever_tool, search]
prompt = hub.pull("hwchase17/openai-functions-agent")
agent = create_openai_functions_agent(self.llm, tools, prompt)
self.agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=self.config.verbose,
)
def chat_with_agent(
self,
message="Can LangSmith help test my LLM applications?",
):
self.create_agent_with_search()
self.agent_executor = self.get_agent()
chat_history = [HumanMessage(content=message), AIMessage(content="Yes!")]
invoke_arg = {"chat_history": chat_history, "input": "Tell me how"}
response = self.agent_executor.invoke(invoke_arg)
print(response["output"])
def get_agent(self):
return self.agent_executor